
A search engine can only investigate the compartment of the web that it has captured and built-in its database. For those of us in SEO, there are a lot of little particulars that fill our days. Without sophisticated search engines, it would be practically not possible to situate anything on the Web without knowing a specific URL.
It is the key to finding specific information on the vast expanse of the World Wide Web. Many times, we forget to sit back and figure out what it all means. Add to that the fact that most search engines optimization were never skilled. But just pulled out things up “on the job, roads”.
And it is no bolt from the blue that most search engine optimization doesn’t in actuality know how a search engine works. Search engines always perform two main tasks first crawling and then create an index of web pages, finally providing the list of the webs pages according to the requirements of the user that he/she gives in the search box.
Difference between Crawling and Indexing
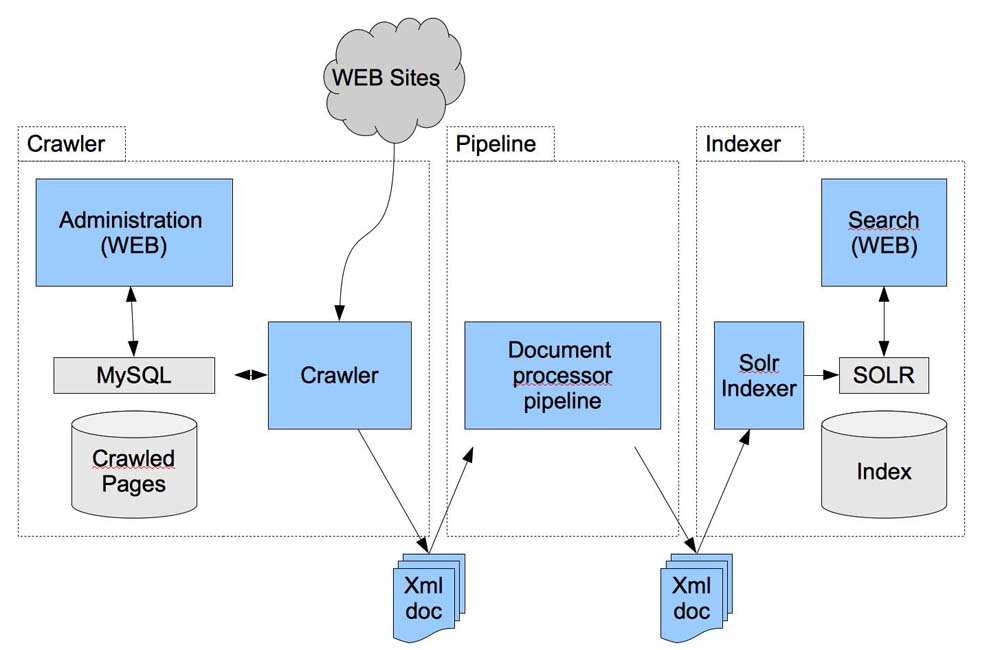
Mostly we read about two words crawling and indexing. On these terminologies, full World Web depends on, and both words have importance in the field of SEO. These words are also called Google Crawling and Google Indexing. There are millions of website in the internet world, so it is impossible, Google check every website post by post data and find the relative data of requirement or eligible for this. So, that’s way Google Administration has made simple Googlebot, which performs these responsibilities.
Crawling

So process in which Googlebot software visits many sites is called crawling. A keyword definition of crawling is:
“Crawling is a method in which Googlebot searching software visits each and every website, discover new and modernized data and report back to Google.”
For Example: Think that worldwide is a network of different roads of a big city with the subway system. A spider or robot has to crawl on routes. There are lots of stops where the spider or robot has to stop; actually, these stops are the document or Web Pages. Getting require result the spider has to crawl the entire road and find the relevant pages according to the conditions of the user.
Indexing
A keyword definition of indexing is:
“Indexing is a process in which the information collected from the website by the Googlebot searching software. It is processed and added to Google Searchable Index”.
For example: When a new document or web page created then the search engine index it as it leaves a robot. You can say it spider that crawl all the new and old relevant documents. And store the links of pages in their database according to the rules that the search engine has defined.
When a user searches anything then the search engine index these pages and shows the result in the form of a list of web pages. This process takes few seconds to perform these tasks.
Search Engine Provide Answer to Every Question
You can say that search engine is like an answering machine as you can ask any question in the form of keyword or query and you can get a result in few seconds.
Search engine proves answer according to this:
- Search engine rank only hoses document or pages that are very close to a search query that user has given.
- The search engine also lists those pages that are famous and popular.
So we can say that the results that are showing to us depend on relevance and fame of web pages.
Did you know?
The first tool of search engine optimization. And it was created in 1990, was called, ‘Archi’. It downloads the bank entertainment guide information of all files to be found on public anonymous FTP servers. It is generating a searchable record of filenames. A year later “Gopher” was fashioning. It indexed basic text documents. “Veronica” and “Jughead” came by the side off to rummage around Gopher’s index systems. The first genuine Web search engine was residential by Matthew Gray in 1993, “Windex.”